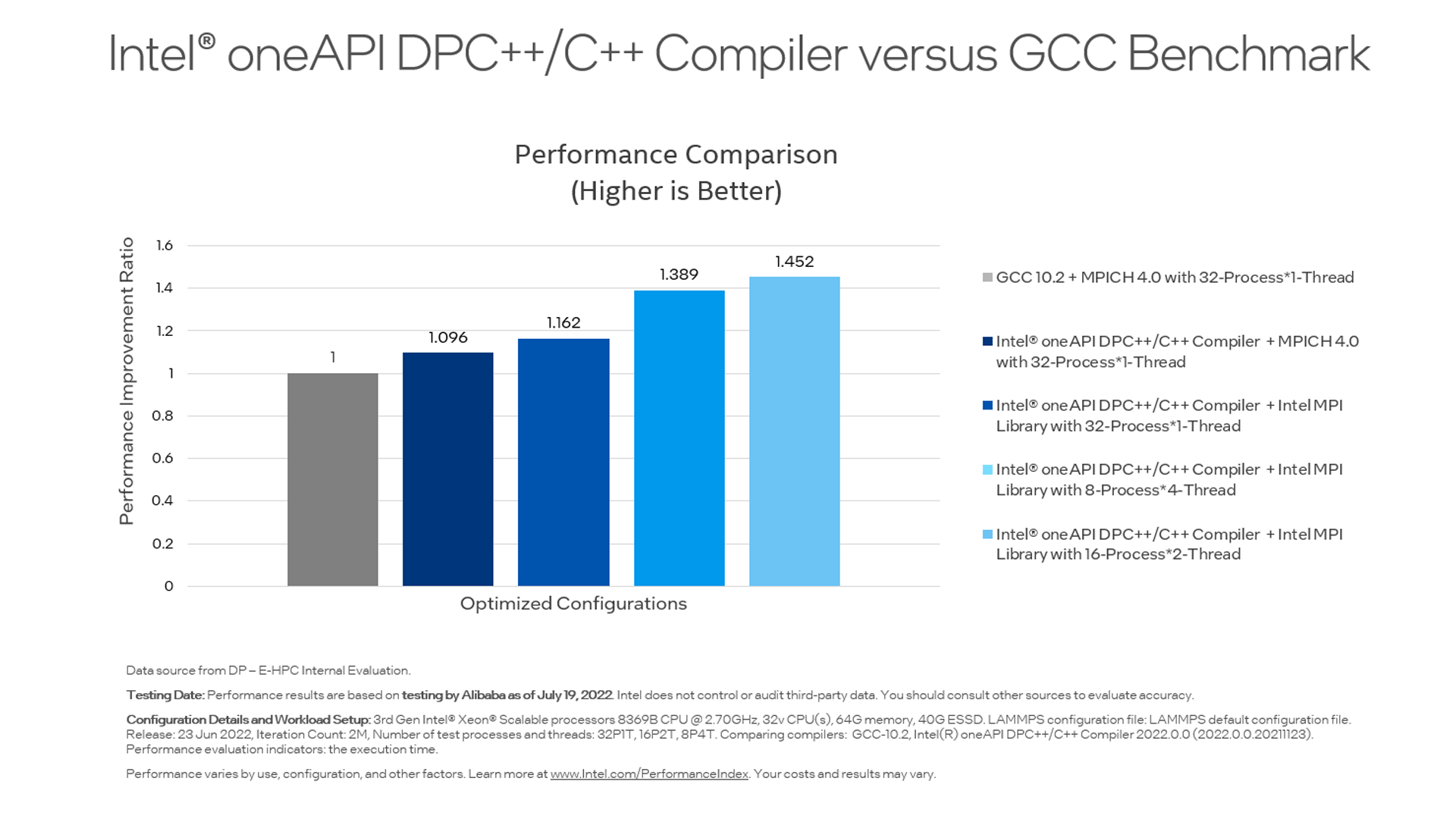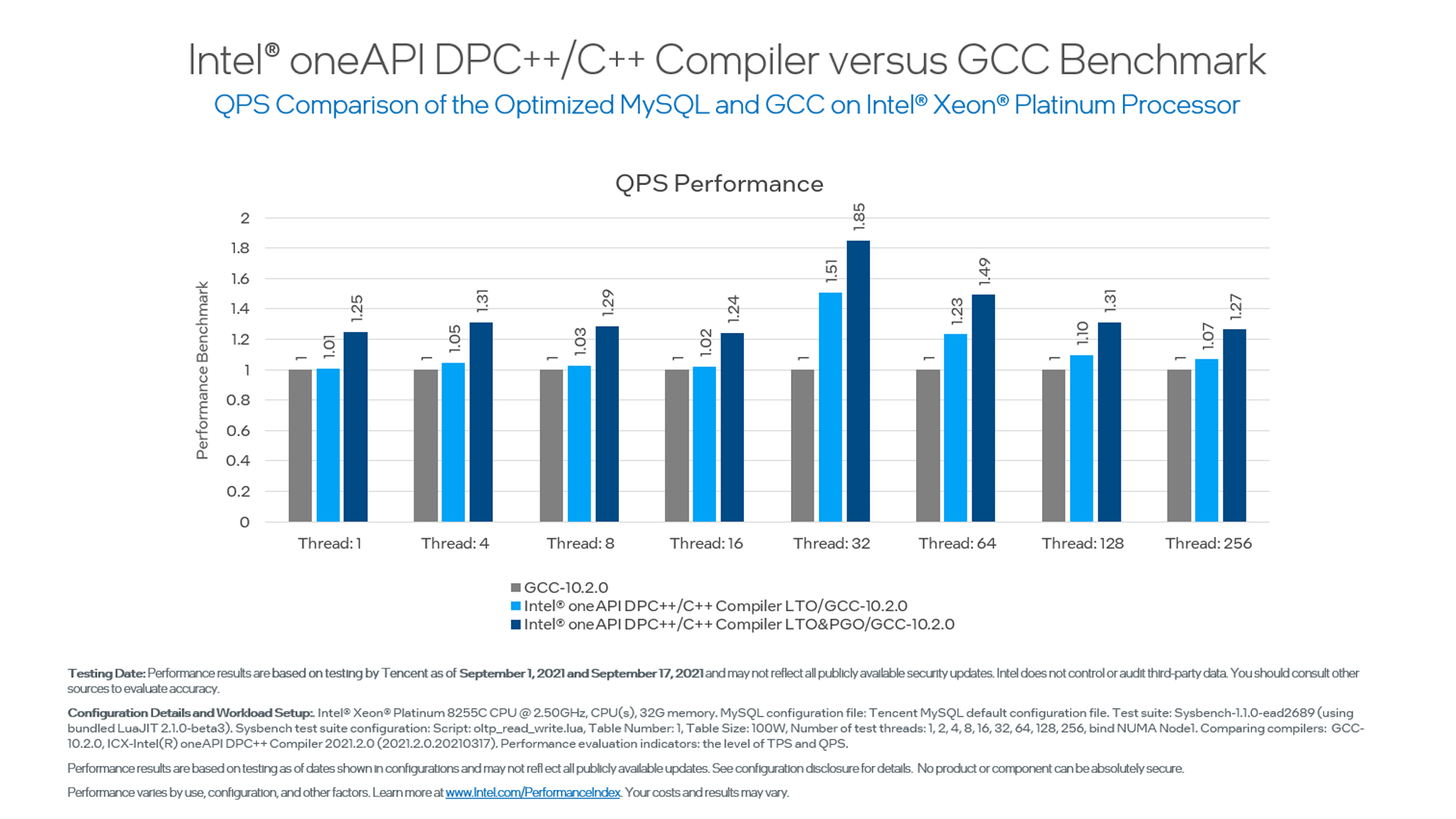
Tencent Gains Up to 85% Performance Boost for MySQL Using Intel® oneAPI Tools
Tencent collaborated with Intel to build a high-performance MySQL on Intel® Xeon® Processors and optimized by the Intel® oneAPI DPC++/C++ Compiler, an advanced compiler in the Intel® oneAPI Base Toolkit.