
Massive Image Dataset Blending Using SYCL with Intel® Data Center GPU Max Series
Story at Glance
- NEON’s Airborne Observation Platform’s (AOP) Color-blending algorithm for photography code is implemented with the SYCL programming model for enhanced portability across diverse computing platforms using Intel® DPC++ Compatibility Tool.
- The migrated C++ with SYCL implementation offers at-par performance with Intel® Data Center GPU Max Series vs. NVIDIA GPU, opening avenues for more accurate and comprehensive scientific investigation using many different platform configurations in the NEON ecosystem.
Introduction
The National Ecology Observatory Network (NEON) periodically collects data from various locations nationwide using Airborne Observation Platforms (AOPs). It is designed to collect long-term open-access ecological data to understand better how U.S. ecosystems are changing. Regarding data management and processing, NEON’s biggest challenge is acquiring, processing, and distributing the AOP data collected periodically from key locations across the nation and contributing to a data collection of hundreds of TBs, which continues to grow exponentially.
This data is subsequently processed using a combination of cloud-based and on-premises computational resources and then shared with the larger scientific community. Researchers at the University of Utah have supported this effort, providing streaming visualization solutions to make this data interactively accessible online (see an example on the NEON data portal).
Challenge of Removing False Seams From Raw Images
The NEON aerial photography data displays noticeable lines or divisions, known as seams, which arise due to variations in lighting conditions during the extensive data collection process. This occurs because the data collection spans vast geographic areas and takes place over extended periods. As a result, the differing lighting conditions at various times and locations contribute to the appearance of these seams in the data. Such seams significantly impact the scientific value of the data since they introduce spurious artifacts in subsequent image analysis and interpretation of the underlying ecology.
Through the application of an iterative solver, the University of Utah’s algorithm enhances the raw image data, effectively removing false seams and providing data products that can be used for scientific investigation.
 Figure 1: Image with and without seams. Original mosaic with seams (left) and after processing (right):
Figure 1: Image with and without seams. Original mosaic with seams (left) and after processing (right):
In Figure 2 below, we apply an edge detection filter to highlight artifacts created by the seams present in the original data. the University of Utah blending results allow us to produce more reliable analysis results (left) when using the same edge detection filter.
 Figure 2. Comparison of image analysis using original and blended mosaics. On top is a detail of the original mosaic (right) and the result of an edge detection filter (left). On the bottom, the University of Utah’s blending results (right) allow us to produce more reliable analysis results (left) using the same edge detection filter.
Figure 2. Comparison of image analysis using original and blended mosaics. On top is a detail of the original mosaic (right) and the result of an edge detection filter (left). On the bottom, the University of Utah’s blending results (right) allow us to produce more reliable analysis results (left) using the same edge detection filter.
Solution
Cross-architecture Intel® Toolkits powered by oneAPI enable single-language and platform applications to be ported to (and optimized for) multiple single and heterogeneous architecture-based platforms.
We have developed a portable color-blending algorithm for photography data based on the Conjugate Gradient (CG) method, a gradient-based manipulation method where gradient information (i.e., rate of value change) from the source images is used to alter pixel values and minimize alterations smoothly. This method involves the solution of a linear system and, in its original implementation, made use of several cuBLAS routines. We implemented it in the SYCL programming model to harness diverse hardware architectures’ computational power, ensuring consistent platform performance and reduced development efforts. In particular, the Intel DCPP++ Compatibility Tool was instrumental in converting several linear algebra routines from cuBLAS to oneMKL.
Implementation and Results
The blending analysis is only one (optional) component of a data processing pipeline developed to provide interactive access and visualization to NEON AOP data. The data pipeline in Figure 3 below periodically checks for new data products that can be served through the AOP interactive viewer (i.e., orthomosaic aerial data composed of hundreds of image files) using the NEON REST API. New data is being downloaded, converted to a str data format that can be streamed, and published on a server. Information about the data converted and the location on the streaming server is stored in a local database.
The NEON data portal queries the AOP viewer data Application Programming Interface (API) to inquire about available data products for streaming. The web viewer embedded in the NEON data portal connects to the corresponding stream of data products and requests tiles for visualization. Components of the University of Utah’s system that expose an Application Programming Interface (API) are in blue, while scripts and processing blocks are in green or red. NEON or third parties manage components in grey.
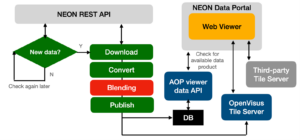 Figure 3. Data Processing Pipeline
Figure 3. Data Processing Pipeline
This blending development is accelerated using the Intel® DPC++ Compatibility Tool, which allows migration of the original CUDA code into SYCL kernels and MKL APIs, as shown below. The entire code was seamlessly transformed with little to zero manual efforts. 99.9% of the code was transformed to SYCL in just a few seconds.
For example:
rho = cublasSdot(N,(float *)_d_p,1,(float *)_d_p,1);
is automatically ported to the following MKL SYCL code:
float *res_temp_ptr_ct1 = sycl::malloc_shared<float>(1,dpct::get_default_queue()); rho = *res_temp_ptr_ct1; oneapi::mkl::blas::column_major::dot(q, N,(float*)_d_p,1,(float *)_d_p,1, &rho).wait();
As well as a CUDA kernel call as:
float_to_char<<<numBlocks_mult, threadsPerBlock>>>(dimx, dimy, _d_xvec, _d_sol_data);
This is ported to the following parallel for construct:
q.parallel_for(
sycl::nd_range<3>(numBlocks_mult ✶ threadsPerBlock, threads PerBlock), [=] (sycl::nd_item<3> item_ct1) {
float_to_char(dimx, dimy, _d_xvec, _d_sol_data, item_ct1);
});
q.wait_and_throw();
This migration transforms the CUDA kernel launch into a parallel_for construct, and the loop body is expressed as a lambda function. The loop iterator is expressed in terms of a sycl::nd_range with 3 dimensions, which is the same dimensionality of the original CUDA thread blocks. The item_ct1 here will be used to identify each thread executing the kernel function.
In the following plot, we report performance for growing problem sizes (from 10’000×10’000 pixels to 40’000×40’000 mosaic) using Intel CPU (Intel® Xeon® Platinum 8480+) and GPU (Intel® Data Center GPU Max 1100) available on the Intel® Developer Cloud and using the original code on an NVIDIA A6000 on a workstation.

Empirical results on the Intel® Developer Cloud (IDC) demonstrate the algorithm’s efficacy in generating high-quality images and efficient, scalable performance across different hardware configurations. Furthermore, the performance on GPU is comparable to the original vendor-optimized code.
Conclusion
A SYCL portable blending algorithm eliminates seams from large aerial imaging mosaics and allows for more accurate science to be performed on ecological survey data sets by the community. The implementation was made using a Poisson solver using a conjugate gradient method implemented originally in CUDA and migrated to the modern vendor agnostic SYCL programming model, allowing experimentation with the same codebase on both CPU and GPUs. The experiment and comparison with the CUDA implementation show the scalable performance of the algorithm and portability across devices. SYCL adoption opens diverse hardware architecture sets, ensuring stable and consistent performance across the board and reducing development and software stack maintenance efforts.
Explore More
- Become part of the effort to make high-performance cross-architecture compute transparent, portable, and flexible. Include SYCL as the accelerator and GPU offload solution in your code path. Adopt oneAPI as the means to implementations free from vendor-lock.
- Get started Intel oneAPI Math Kernel Library (oneMKL).
Additional SYCL Resources
- Academic oneAPI Centers of Excellence
- Essentials of SYCL*
- CUDA* to SYCL* Catalog
- Migrate from CUDA* to C++ with SYCL*
- Workflow for a CUDA* to SYCL* Migration
- An Awesome List of oneAPI Projects
- SYCLomatic