
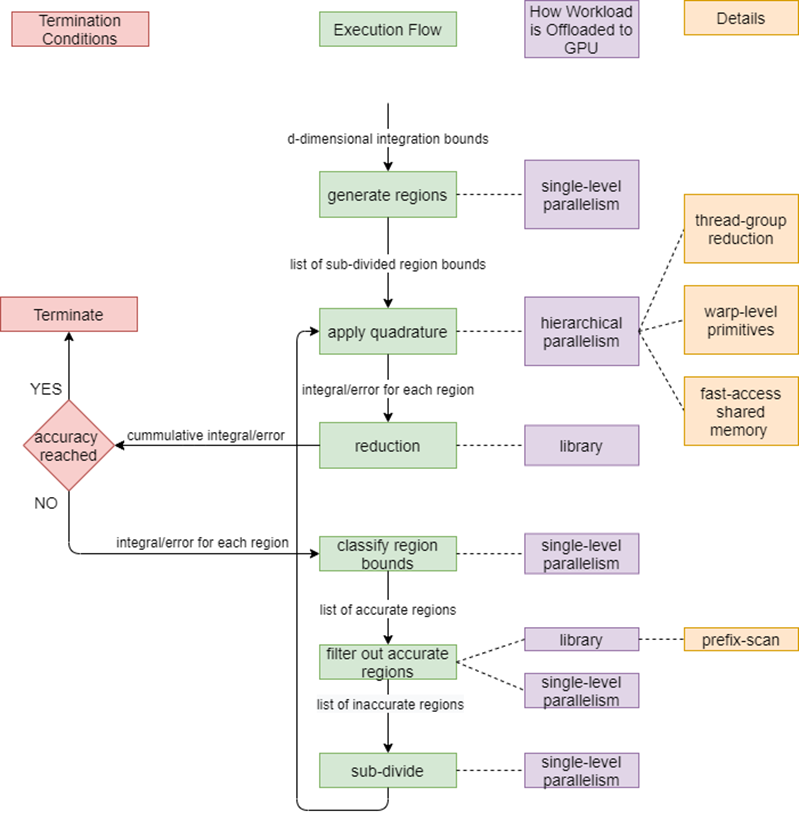

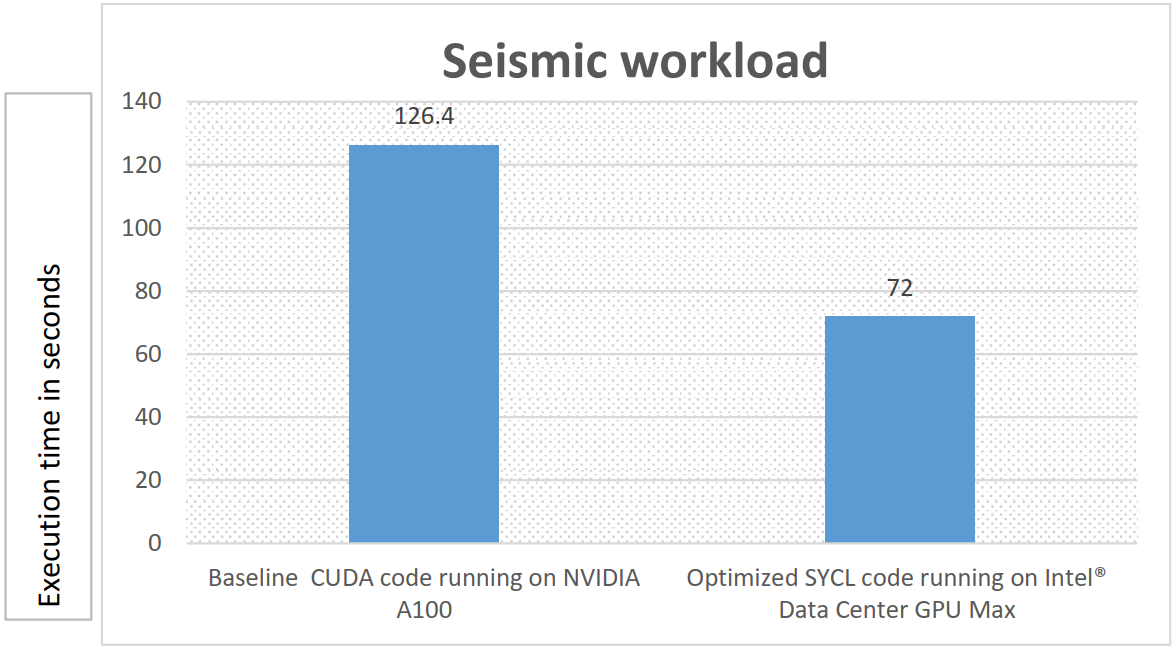

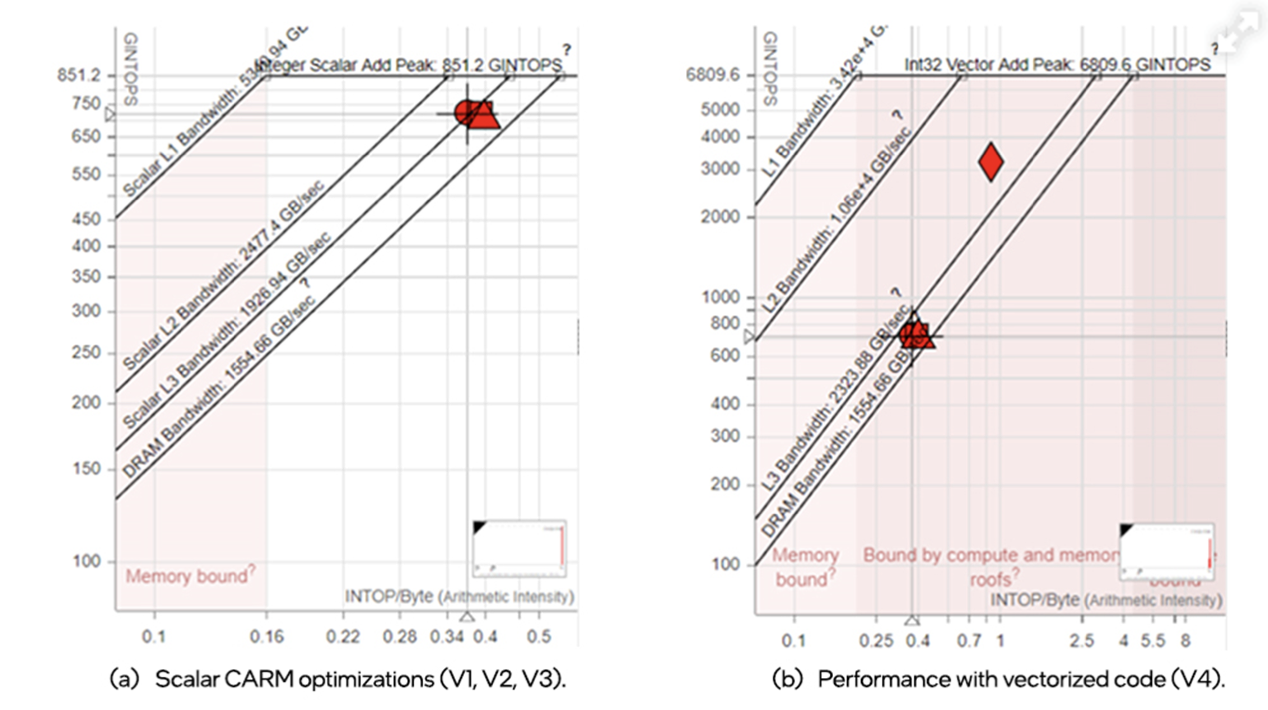
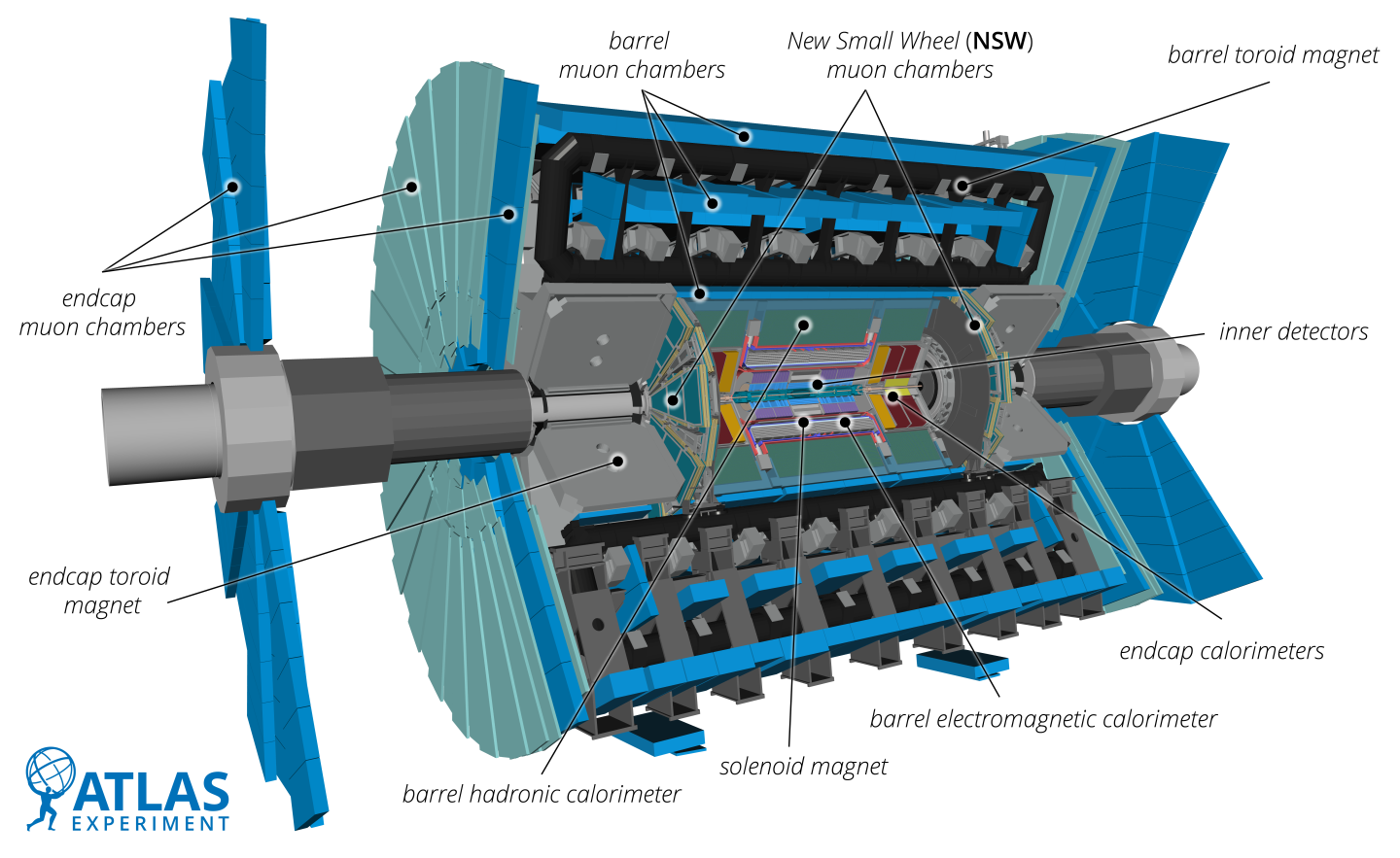
Using Intel® oneAPI tools, the ATLAS Experiment at the Large Hadron Collider is on track to achieve many-fold performance improvements using multi-architecture CPU+GPU systems in processing future data from the detector.

Using AI to speed diagnostics for individuals or larger populations involves complex computing models that benefit from accelerated computing systems built on a mix of CPUs, GPUs, and other specialty processors. Over the past two years since the onset of COVID-19, several healthcare organizations and technology providers have found that Intel oneAPI and AI tools efficiently accelerate applications requiring high-performance, multiarchitecture computing.
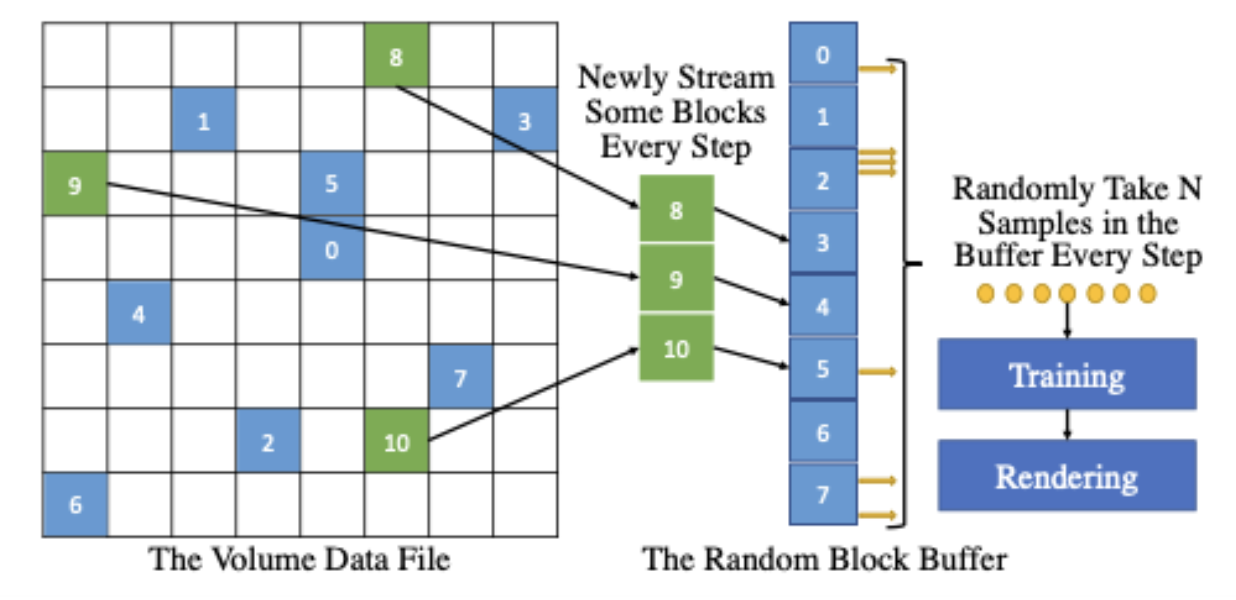
“Our ability to exploit cutting edge AI and machine learning technologies allows us to readily meet the fast-growing demands of big data and scientific visualization applications.” Kwan-Liu Ma (PI) – Professor, Computer Science Director, UC Davis Center for Visualization Head, VIDI Labs Faculty of GGCS, GGE, and ECEGP.


TACC’s Frontera Supercomputer uses oneAPI multiarchitecture programming to accelerate scientific advancements.
