
C-DAC Achieves 1.75x Performance Improvement on Seismic Code Migration from CUDA on Nvidia A100 to SYCL on Intel® Data Center GPU Max Series
Summary
The India-based premier R&D organization used tools in the Intel® oneAPI Base Toolkit to free itself from vendor hardware lock-in by migrating its open-source seismic modeling application from CUDA to SYCL. As a result, application performance improved by 1.75x on Intel® Datacenter GPU Max 1550 when compared to NVIDIA A100* platform performance.
Introduction
C-DAC (Center for Development of Advanced Computing) is the premier R&D organization of India’s Ministry of Electronics and Information Technology for R&D in IT, Electronics, and associated areas. Created in 1987, its research spans multiple industries and domains such as HPC, cloud computing, embedded systems, cyber security, bioinformatics, geomatics, and quantum computing.
In the realm of geophysical exploration, C-DAC has developed an open-source seismic modeling application, SeisAcoMod2D.—it performs acoustic wave propagation of multiple source locations for the 2D subsurface earth model using finite difference time domain modeling.
Challenge: Vendor Hardware Lock-In
Fueled by high computational throughput and energy efficiency, there has been a quick adoption of GPUs as computing engines for High Performance Computing (HPC) applications in recent years. The growing representation of heterogeneous architectures combining general-purpose multicore platforms and accelerators has led to the redesign of codes for parallel applications.
SeisAcomod2D is developed in C to efficiently use the multicore CPU architecture and in CUDA* C to make use of NVIDIA GPU architecture. The existing CUDA C program cannot run Intel® GPUS (nor any other vendor GPUs, for that matter). This limits architecture choice, creates vendor lock-in, and forces developers to maintain separate code bases for CPU and GPU architectures.
Solution: Build a Single Code Base using Intel® oneAPI Tools
Intel® oneAPI tools enable single-language and cross-architecture platform applications to be ported to (and optimized for) multiple single and heterogeneous architecture-based platforms. Using a combination of optimized tools and libraries, the application’s native CUDA code was migrated to SYCL*, enabling it to run seamlessly on Intel® CPUs and GPUs.
The result: SeisAcoMod2D is now comprised of a single code base that can be used to run it on multiple architectures without losing performance. This was a perfect package for C-DAC: a single language with a boost in performance without being vendor-locked.
Let’s walk-through the steps, tools, and results.
Code Migration to CUDA
SeisAcoMod2D has both CPU (C++) source and GPU (CUDA) source. As a first step, the Intel® DPC++ Compatibility Tool (available as part of the Intel® oneAPI Base Toolkit) was used to migrate CUDA source to SYCL source. In this case, the Compatibility Tool was able to achieve 100% migration in a very short time. This made functional porting of the seismic modeling complete. Figure 1 and Figure 2 provide the snippet of CUDA source code to migrated SYCL source code.
 Figure 1: Snippet of CUDA source before migration
Figure 1: Snippet of CUDA source before migration
 Figure 2: Snippet of SYCL source after migration
Figure 2: Snippet of SYCL source after migration
Due to the presence of multiple CUDA streams with async calls, the migrated code needed placement of appropriate barrier/wait calls or single SYCL queue to maintain the data consistency. Incorporating these solutions resolved the correctness issue, the changes shown in Figure 3 and Figure 4.
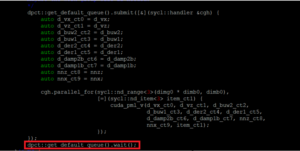 Figure 3: Placement of wait call
Figure 3: Placement of wait call
DPC++ Compatibility Tool migration from CUDA streams to SYCL queues:
![]()
User modification of multiple SYCL queues to single SYCL queue:
 Figure 4: Single SYCL queue creation
Figure 4: Single SYCL queue creation
Our open-source Seismic Modeling application – ‘SeisAcoMod2D’ CUDA code was migrated to SYCL using SYCLomatic easily. The migrated code efficiently runs on Intel® Data Center GPU Max Series and achieves competitive performance compared to currently available GPU solutions. As we look to the future, the combination of Intel® Xeon Max CPUs with High Bandwidth Memory plus Intel Data Center GPU Max Series presents us with a seamless upgrade path, accelerating our applications without the need for code changes thanks to using oneAPI Toolkits.