
Oak Ridge National Laboratory Establishes oneAPI Center for Excellence
Dr. Zheming Jin, a research scientist at Oak Ridge National Laboratory (ORNL), is leading ORNL’s effort to study how various approaches to parallel programming, including SYCL using Data Parallel C++ (DPC++), HIP, CUDA, and OpenMP, interact with the underlying hardware on which it runs. Dr. Zheming is an expert on high-level synthesis and heterogeneous parallel computing. His previous work demonstrated that FPGAs are a promising heterogeneous computing component for supercomputing (for example, see Toward Evaluating High-Level Synthesis Portability and Performance between Intel and Xilinx FPGAs[1]). He is the creator of the oneAPI Direct Programming Repository, a valuable research tool for High Performance Computing (HPC) middleware developers. This freely available repository contains approximately 200 benchmarks (and growing) for evaluating performance of the above various coding approaches. The repository is a veritable Rosetta Stone of heterogenous parallel programming samples that can help developers use oneAPI open, standards-based, cross-architecture programming and contribute to improve open source project communities, including the DPC++ compiler project to implement SYCL in LLVM.
Progress Toward a Unified, Cross-Architecture Programming Model
With the emergence and evolution of diverse and capable heterogeneous compute technologies, parallel programming models continue to evolve to take advantage of these capabilities through various heterogeneous programming approaches. Different parallel programming models and APIs used today include OpenMP, SYCL, HIP, OpenCL and most recently oneAPI.
According to oneAPI.io,
oneAPI is a cross-industry, open, standards-based unified programming model that delivers a common developer experience across accelerator architectures — for faster application performance, more productivity, and greater innovation.
oneAPI builds on existing models and industry standards. It includes support for SYCL, via the DPC++ project, a set of library APIs, and a low-level hardware interface to run kernels across CPUs, GPUs, FPGAs, and other accelerators used in general computing and artificial intelligence (AI) and deep learning (DL).
Since its launch a few years ago, oneAPI has gained traction across the software ecosystem. Individual developers[2] are using oneAPI to develop their codes, independent software vendors (ISVs) are building compilers and tools to deploy SYCL code to targeted devices, and even OEMs[3] (Dell, HP, Lenovo) are building data science mobile and desktop workstations that use oneAPI tools to accelerate AI development. oneAPI supports CPUs and GPUs and other accelerator architectures from multiple vendors including Intel. The ecosystem is expanding support and usage. Examples include:
· The Intel® DPC++ Compatibility Tool assists migrating code written in CUDA to use DPC++.
· Codeplay’s contributions to the open-source DPC++ LLVM project allow developers to target NVIDIA GPUs using SYCL code without intermediate layers.[4]
· Heidelberg University’s[5] work on hipSYCL 0.9.0 incorporated SYCL 2020 specification features innovated in DPC++ for AMD GPUs and delivered compiler support in the 0.9.1 version where developers can compile to a single binary that can run on CPUs, Nvidia GPUs, and AMD GPUs.
· Fujitsu’s Fugaku supercomputer is using oneAPI Deep Neural Network Library (oneDNN) with ARM architecture.[6]
· Huawei is extending DPC++ with support for its Ascend AI chipset.[7]
· NERSC (National Energy Research Scientific Computing Center at Lawrence Berkeley National Lab (Berkeley Lab) and Argonne Leadership Computing Facility (ALCF) are working with Codeplay to enhance the LLVM SYCL GPU compiler capabilities for NVIDIA A100 GPUs.[8]
· Argonne National Labs (ANL) in collaboration with Oak Ridge National Laboratory (ORNL) is having Codeplay implement the DPC++ compiler, an implementation of the SYCL open standard, to support AMD GPU-based supercomputers.[9]
· Sberbank is providing oneAPI for AI development in its Sbercloud platform[10]
· Chinese Academy of Sciences is extending the oneAPI unified programming framework to support Chinas’ local accelerators.
Developing the oneAPI Direct Programming Repository
As more ISVs develop products using the oneAPI specification, they need standardized benchmarks written in different ways to measure and compare code performance and productivity — and thus value. Dr. Zheming built this rich repository of such benchmarks at github.com/zjin-lcf/oneAPI-DirectProgramming. His work evaluates oneAPI direct programming based on SYCL/DPC++ and OpenMP (Table 1).
“oneAPI is an interesting model worth studying,” Dr. Zheming explained. “But we don’t have a lot of open-source programs to study SYCL implementations. We have many CUDA and OpenMP programs targeting different devices, like NVIDIA GPUs, but not enough that can be used to compare against SYCL.”
Currently, the repository contains about 200 different codes (Table 1) written in SYCL/DPC++, CUDA, and OpenMP. Some of these come from the Rodinia benchmark suite, including Kmeans, Heart Wall, Particle Filter, and Back Propagation, among others. Refer to the full GitHub list for sources and other information important to the repository.
 Table 1. List of test codes at https://github.com/zjin-lcf/oneAPI-DirectProgramming
Table 1. List of test codes at https://github.com/zjin-lcf/oneAPI-DirectProgramming
“Rodinia is a popular benchmark suite used by researchers that target accelerators,” Dr. Zheming added. “Most codes in Rodinia include OpenMP, CUDA, and OpenCL implementations. But codes within the Rodinia suite didn’t have SYCL implementations to compare performance or productivity across different programming models. I started with some codes from Rodinia.”
Dr. Zheming wanted benchmarks between different implementations to be as fair as possible. So, his goal was to create codes that are as functionally equivalent as possible, i.e., without special optimizations that might cater to a particular manufacturer’s device.
OpenMP is widely used across the ecosystem for shared-memory parallelism. The OpenMP standard continues to evolve. Since 2015, support for targeted device offloading to GPUs has been added. ISVs, including Intel, continue to enhance their compilers for it.
For the repository, Dr. Zheming created CUDA versions from open-source files, and then ported those codes to DPC++ using the Intel DPC++ Compatibility Tool. The tool helps developers migrate code written in CUDA to DPC++ with 90 to 95 percent[11] of the code automatically transitioning to DPC++. CUDA language kernels and library API calls are also ported over.
“There are many CUDA programs for parallel computation,” Dr. Zheming continued. “It’s important that we have a tool to help port them to SYCL/DPC++ so they can be run across different architectures.”
The Intel DPC++ Compatibility Tool is part of the Intel oneAPI Base Toolkit, which he used. Because different CUDA implementations can access data either through device buffers or shared memory, he produced two versions of the converted code.
· For codes in the repository with “‑dpct” suffixes, memory management migration was implemented using both the explicit and restricted Unified Shared Memory extension.
· Codes with the “-dpct-h” suffix use Intel DPC++ Compatibility Tool header files.
Additionally, he wrote SYCL versions using SYCL buffers. Then he ran the codes on Intel® processor-based platforms.
Evaluating the Codes on Intel® CPUs and GPUs
Using Intel resources, Dr. Zheming evaluated the four codes (SYCL, both dpct-generated device buffer or shared memory versions, and OpenMP) on two different Intel processor-based platforms with Intel integrated graphics:
· Intel Xeon E3–1284L processor with Intel P6300 graphics (Gen8)
· Intel Xeon E2176G processor with Intel UHD630 graphics (Gen9.5)
He used the Intel OpenCL intercept layer to monitor the following using the OpenCL plugin interface:
· Total enqueue — indicates the total number of low-level OpenCL enqueue commands called by a parallel program. These enqueue commands include clEnqueueNDRangeKernel, clEnqueueReadBuffer, and clEnqueueWriteBuffer.
· Host timing — the total elapsed time of executing OpenCL API functions on a CPU host.
· Device timing — the total elapsed time of executing OpenCL API functions on a GPU device.
Experimental results from both platforms are listed in the repository. The results show that for most of these codes, performance across the Intel DPC++ Compatibility Tool and SYCL implementations differs only slightly. This is not surprising considering they are similar in approach. However, compared to OpenMP, the oneAPI codes had fewer calls and ran faster.
Figure 1 compares results of a few of these benchmark codes. Because the measurements differ in units (# of calls, seconds, and milliseconds), the table is normalized to the OpenMP implementation.
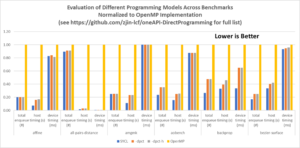 Figure 1. Partial benchmark results from repository codes normalized to OpenMP. See the full list at GitHub.
Figure 1. Partial benchmark results from repository codes normalized to OpenMP. See the full list at GitHub.
Highlighted Results
Dr. Zheming’s oneAPI performance studies are documented in several reports[12], which show improved performance using SYCL on Intel CPUs and GPUs and higher coding productivity. For example, comparing SYCL and OpenCL implementations of Heart Wall and Particle Filter, a SYCL implementation of Heart Wall ran 15 percent faster on Intel® Iris® Pro Graphics than an OpenCL implementation, while the Particle Filter SYCL code ran 4.5X faster on an Intel Xeon processor with four cores.4 Both programs required 52 percent (for Heart Wall) and 38 percent (for Particle Filter) fewer lines of code, making actual programming more productive.4
The oneAPI Direct Programming Repository is an ongoing work that began with studying the Rodinia benchmark to understand how to migrate programs to oneAPI and evaluate the benefit of the new programming model on Intel architectures. Dr. Zheming encourages other developers creating similar benchmarks to consider merging GitHub projects for the benefit of the community, which could further help evolve SYCL, C++, libraries, and the compilers (including DPC++).
Dr. Zheming’s work continues with the oneAPI Center of Excellence (CoE) at ORNL announced in October this year.[13] This new oneAPI CoE will focus on helping developers to migrate their codes to oneAPI. Dr. Zheming will be expanding the open-source repository and studying how these samples interact with the underlying hardware. Intel will then work with him to bring these learnings out broadly to the developer community through training courses, workshops, and speakerships.
[1] Also see http://ix.cs.uoregon.edu/~jlambert/papers/cabrera_iwocl_2021_slides.pdf.
[2] See projects at https://devmesh.intel.com/projects
[3] https://www.intel.com/content/www/us/en/newsroom/news/innovation-computing-news.html
[4] https://www.codeplay.com/portal/press-releases/2020/04/22/codeplay-s-contribution-brings-nvidia-support-for-sycl-developers.html
[5] https://www.phoronix.com/scan.php?page=news_item&px=oneAPI-AMD-Radeon-GPUs and https://arstechnica.com/gadgets/2020/09/intel-heidelberg-university-team-up-to-bring-radeon-gpu-support-to-ai/ and https://hipsycl.github.io/hipsycl/sycl2020/release/hipsycl-0.9/
[6] https://www.oneapi.io/event-sessions/ai-a-deep-dive-into-a-deep-learning-library-for-the-a64fx-fugaku-cpu-meet-the-developer/
[7] https://dl.acm.org/doi/10.1145/3456669.3456684
[8] https://www.nersc.gov/news-publications/nersc-news/nersc-center-news/2021/nersc-alcf-codeplay-partner-on-sycl-for-next-generation-supercomputers/
[9] https://www.alcf.anl.gov/news/argonne-and-oak-ridge-national-laboratories-award-codeplay-software-further-strengthen-sycl
[10] https://www.sberbank.ru/en/press_center/all/article?newsID=b687be07-6725-421f-817e-a8b6d0bde424&blockID=1539®ionID=77&lang=en&type=NEWS
[11] Intel estimates as of September 2021. Based on measurements on a set of 70 HPC benchmarks and samples, with examples like Rodinia, SHOC, PENNANT. Results may vary.
[12] https://publications.anl.gov/anlpubs/2019/12/157485.pdf. Also see https://publications.anl.gov/anlpubs/2019/12/157540.pdf and https://ieeexplore.ieee.org/document/9005555
[13] https://download.intel.com/newsroom/2021/client-computing/oneAPI-Fact-sheet.pdf
Bringing Nvidia® and AMD support to oneAPI
Developers can write SYCL™ code and use oneAPI to target Nvidia* and AMD* GPUs with free binary plugins Today is a milestone for me as...

Free Your Software from Vendor Lock-in Using SYCL and oneAPI
Using automated tools, open-source software, the SYCL programming model and oneAPI to enable multiple processor targets were topics covered by Codeplay experts at Intel Vision...
Expanding our Open Standards Vision with Intel®
Today Intel announced, pending final approvals, that it would acquire Codeplay Software. This is an exciting moment for the industry and will help enable the...