
CFD Poisson Solver achieved up to 1.9x Performance Improvement by Migrating from CUDA to SYCL
Summary
IIT-Goa (Indian Institute of Technology, Goa), the Premier Indian Academic Institute, used tools in the Intel® oneAPI Base Toolkit to free itself from vendor hardware lock-in by migrating its 2D Poisson Equation Solver from CUDA to SYCL. As a result, the solver’s performance improved by 1.9x on Intel® Data Center GPU Max 1550 compared to the performance on Nvidia*A100 GPU.
Introduction
IIT-Goa (Indian Institute of Technology, Goa) is a premier academic Institute of India’s Ministry of Human Resource and Development, offering state-of-the-art education, research, and training in science and technology to impact society, environment, and global challenges.
In the real world, the Navier-Stokes (N.S.) equation governs most physical processes. However, it remains the billion-dollar unsolved equation in the mathematics community since there is no exact solution to the equation. However, scientists in the CFD community have been developing N.S. solvers to study the flow field of various physical processes with the help of numerical methods in mathematics. Since it is difficult to test the functionality of the solvers straight away due to the complexity of the space and time variables in the N.S. equation, a Poisson equation is used as the standard test solver across the scientific domain. The Poisson equation itself acts as the standard governing equation for different physical phenomena like heat transfer study or study of diffusion processes. Hence, we have used a 2D Poisson equation developed by IIT Goa for our performance portability study using oneAPI and perhaps later extend the study to high-end state-of-the-art CFD solvers. 
Figure 1. Sample Computational Stencil and mapping to 1D Array
Challenge: Vendor Hardware Lock-In
Fueled by high computational throughput and energy efficiency, GPUs have been quickly adopted as computing engines for High Performance Computing (HPC) applications in recent years. The growing representation of heterogeneous architectures combined with general purpose multicore platforms and accelerators has led to the redesign of codes for parallel applications.
The Poisson equation is developed in C to efficiently use the multicore CPU architecture and in CUDA* C to use Nvidia*GPU architecture. The existing CUDA C program cannot run on any other hardware architecture GPU or accelerator apart from Nvidia*GPU. This limits the choice of different architectures, creates vendor lock-in and forces developers to maintain separate code bases for CPU and GPU architectures.
Solution: Build a Unified Code Base using Intel® oneAPI Tools
Intel® oneAPI tools enable unified-language and cross-architecture platform applications to be ported to (and optimized for) multiple heterogeneous architecture-based platforms. Using Intel® oneAPI tools and libraries, the CUDA native application is migrated to SYCL, enabling it to run seamlessly on multiple architectures like Intel® CPUs, Intel GPUs, and Nvidia*GPU.
The result: The migrated SYCL version of The Poisson equation solver now comprises a unified code base that can be used to run it on multiple architectures without losing performance or accuracy. Optimizations enabled this solution to be more lucrative as it delivers a unified code base with a boost in performance without being vendor locked.
Code Migration to SYCL
The Poisson Equation Solver has CPU (C++) and GPU (CUDA) sources. As a first step, the Intel® DPC++ Compatibility Tool (available as part of the Intel® oneAPI Base Toolkit) was used to migrate CUDA source to the SYCL source. In this case, the Compatibility Tool achieved 100% migration in a very short time. This made functional porting complete. Figure 2 and Figure 3 provide the snippet of CUDA source code to migrated SYCL source code.
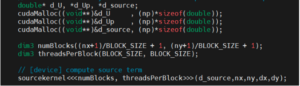 Figure 2. Snippet of CUDA source before migration
Figure 2. Snippet of CUDA source before migration
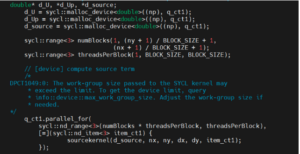 Figure 3. Snippet of SYCL source after migration
Figure 3. Snippet of SYCL source after migration
Our research group at IIT Goa has developed an in-house CFD solver to simulate incompressible turbulent flows. To port our solver to GPUs, we are working with the unsteady Poisson equation, a model template for our CFD solver. The Poisson equation code is developed in CUDA, limiting its execution to vendor-specific GPUs. Using the SYCLomatic tool of Intel® oneAPI= tools, this code is migrated to SYCL, thus opening up other vendor and architectural alternatives. After further optimization, the migrated code runs on Intel® Data Center GPU Max 1550 and achieves ~1.9x speedup compared to the existing GPU solution. We look forward to using the migrated SYCL code on different platform architectures and migrating our CFD solver to SYCL. – IIT Goa, India
Running and Validating Results Optimization
As a next step, migrated SYCL code is compiled with Intel® oneAPI DPC++/C++ Compiler to generate the executable. To compile the code for NVIDIA*GPUs, Codeplay*’s oneAPI for NVIDIA*GPUs plugin is used, which adds support for NVIDIA* GPUs to the Intel® oneAPI Base Toolkit. The executable executes till a convergence criterion is met. The result was validated by comparing it with the results generated by the CUDA executable.
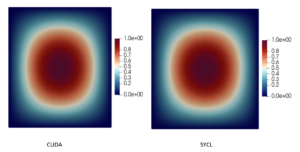 Figure 4. Plots of the output results from the original CUDA code and migrated SYCL code.
Figure 4. Plots of the output results from the original CUDA code and migrated SYCL code.
Performance Results and Optimization on Nvidia*A100 GPU
The migrated SYCL code was run on Nvidia*A100 GPU, and some performance degradation was seen when compared to the CUDA code.
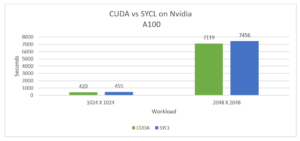 Figure 5. Performance comparison of optimized SYCL code against CUDA code on Nvidia*A100
Figure 5. Performance comparison of optimized SYCL code against CUDA code on Nvidia*A100
To identify the performance regression in the SYCL code, we used the Nsight* Systems profiler to generate application profile for both CUDA as well as SYCL code base and did a deeper analysis of the same.
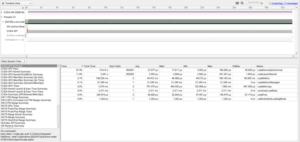 Fig 6. CUDA API Summary of CUDA code on Nvidia*A100
Fig 6. CUDA API Summary of CUDA code on Nvidia*A100
 Fig 7. CUDA API Summary of migrated SYCL code on Nvidia*A100
Fig 7. CUDA API Summary of migrated SYCL code on Nvidia*A100
In the CUDA API Summary part of the generated profile for SYCL code, it was observed that there were unnecessary calls to 3 functions, namely cuEventCreate, cuEventRecord, and cuEventDestroy_v2. Intel® oneAPI DPC++/C++ Compiler unnecessarily created these events for the NVIDIA*Backend.
To overcome this, we have used an extension that introduces a discard events property (ext::neAPI::property::queue::discard events) for SYCL queues. SYCL queues are used to submit work to the device. Each work on completion returns an event that can be used in the application for synchronization and other purposes such as event-based dependence. By using the discard events property, the application informs a SYCL implementation that it will not use the event returned by any of the queue member functions.
After incorporating the changes, those extra calls to 3 functions (cuEventCreate, cuEventRecord, and cuEventDestroy_v2) were eliminated and achieved a 6% performance improvement.
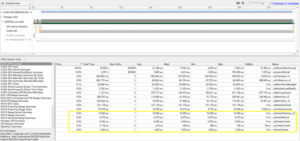 Fig 8. CUDA API Summary of migrated SYCL code after optimization on Nvidia*A100
Fig 8. CUDA API Summary of migrated SYCL code after optimization on Nvidia*A100
 Fig 9. Performance comparison of optimized SYCL code against CUDA code on Nvidia*A100
Fig 9. Performance comparison of optimized SYCL code against CUDA code on Nvidia*A100
Performance Results on Intel® Data Center GPU Max 1550: Significant Improvement
Migrated SYCL code compiled with Intel® oneAPI DPC++/C++ Compiler to generate binary to run on Intel® Data Center GPU Max 1550.
The migrated SYCL code of 2D Poisson Equation Solver performed ~1.9x faster on Intel® Data Center GPU Max 1550 in comparison to CUDA code on Nvidia*A100 GPU.
 Fig 10. Performance comparison of SYCL code on Intel® Data Center GPU Max against CUDA code on Nvidia*A100
Fig 10. Performance comparison of SYCL code on Intel® Data Center GPU Max against CUDA code on Nvidia*A100
Workload: 2D Poisson Equation Solver with 2 Problem Sizes
- Point per block = 1024 x 1024 , Number of Blocks = 32 x 32
- Point per block = 2048 x 2048 , Number of Blocks = 32 x 32
Hardware configuration:
- Intel® Data Center GPU Max Series, with 2 stacks suitable for HPC and AI workloads. This GPU contains a total of 8 slices, 128 Xe-cores, 1024 Xe Vector engines, 128 ray tracing units, 8 hardware contexts, 8 HBM2e controllers, and 16 Xe-links.
- Intel® Xeon® Platinum 8360Y CPU @ 2.40GHz having 72 physical cores,256 GB of DDR4 memory @ 3200 MT/s.
- Nvidia*A100 having 80GB HBM2e, base clock:1065MHz connected to Intel® Xeon® Platinum 8360Y CPU.
Software configuration:
- Operating system: RHEL 8
- Compilers: Intel® oneAPI DPC++/C++ Compiler 2023.0.0 , NVIDIA* CUDA Compiler (NVCC) 12.0
- Language and API: C, SYCL, CUDA C
Conclusion
Intel Intel® oneAPI tools made migrating CUDA source code to SYCL easier, which helped IIT Goa overcome vendor-lock-in for its 2D Poisson Equation Solver and maintain a single code base for different architectures. Nvidia* Nsight Systems tool helped identify the performance regression in SYCL binary running on Nvidia*GPU. By fixing this regression, the SYCL binary running on Nvidia*A100 roughly matched the performance of CUDA binary running on Nvidia*A100. The performance of SYCL binary on Intel® Data Center GPU Max 1550 was ~1.9x that of CUDA binary on Nvidia*A100 GPU. The SYCL code was functional on the AMD HIP Backend as well, but performance evaluation is still pending. Migration of the same code to the ARM backend is also planned in the future.
Explore More
Download the tools
- Get the full complement of Intel oneAPI tools in the Intel oneAPI Base Toolkit.
- Or download standalone:
Get the code samples [GitHub]