
Accelerate PyTorch with IPEX and oneDNN using Intel BF16 Technology
Introduction
Intel and Facebook previously collaborated to enable BF16, a first-class data type in PyTorch. It supports basic math and tensor operations and adds CPU optimization with multi-threading, vectorization, and neural network kernels from oneAPI Deep Neural Network Library (oneDNN, formerly known as MKL-DNN). The related work was published in an earlier blog during the launch of the 3rd Gen Intel® Xeon® scalable processors (formerly codename Cooper Lake). In that blog, we introduced the HW advancements for native BF16 support in Cooper Lake with BF16->FP32 fused multiply-add (FMA) Intel® Advanced Vector Extensions-512 (Intel® AVX-512) instructions that bring doubled theoretical compute throughput over FP32 FMA. Based on the HW advancement and SW optimization from Intel and Facebook, we showcased 1.40x-1.64x performance boost of PyTorch BF16 training over FP32 from DLRM, ResNet-50 and ResNext-101–32x4d, representative deep learning (DL) models for recommendation and computer vision tasks.
In this blog, we introduce the latest two SW advancements added in Intel Extension for PyTorch (IPEX) on top of PyTorch and oneDNN for PyTorch BF16 CPU optimization:
- Ease-of-use Python user-facing API on top of PyTorch to further simplify the usage of BF16 and oneDNN optimization. Previously, users had to insert explicit type conversions from FP32 to BF16 for input tensors to enable BF16 computation. For input tensors to PyTorch ops not supporting BF16, explicit type conversions back to FP32 are also required. In addition, to get the most performance from oneDNN, tensors are preferred to keep in the blocked layout when flowing through ops optimized by oneDNN. To take advantage of oneDNN optimization, users are required to insert explicit tensor layout conversions between the blocked layout and public “strided” layout at the boundary of oneDNN and non-oneDNN ops. Both explicit type conversion and explicit layout conversion would incur non-trivial DL model code changes and hurt user experience. The new IPEX API frees users from model changes by automating these conversions.
- Graph fusion optimization to further boost BF16 inference performance with oneDNN fusion kernels. Graph-level model optimization is becoming more and more important for maximizing DL workload performance when individual compute-intensive ops are well optimized and more varieties of DL topology patterns are innovated. PyTorch started to support graph mode from 1.0 release and the support is getting mature recently for DL inference. oneDNN also brings fusion kernels for DL fusion patterns like conv and matmul with element-wise post-ops. We added graph rewrite pass to IPEX based on PyTorch graph intermediate representation. The optimization pass recognizes these oneDNN-supported common fusion patterns and replaces the corresponding sub-graphs with calls to oneDNN fusion kernels.
The following chapters are organized as follows. We first introduce IPEX and oneDNN as the background info. Then we introduce the ease-of-use IPEX API with examples and briefly explain the internal implementation that supports the API. After that, we show the performance result of PyTorch BF16 training and inference with IPEX and oneDNN on a couple of representative DL models. We conclude with remarks on the next steps.
Background
Intel Extension for PyTorch (IPEX)
Intel closely collaborates with Facebook to contribute optimizations to the PyTorch community and commits to continuously optimize PyTorch with future advancements of Intel HWs. PyTorch brings a modular design with registration API that allows third parties to extend its functionality, e.g. kernel optimizations, graph optimization passes, custom ops etc., with an extension library that can be dynamically loaded as a Python module or from C++ as a shared library. IPEX is such a PyTorch extension library, an open source project maintained by Intel and released as part of Intel® AI Analytics Toolkit powered by oneAPI.
IPEX brings the following key features:
- Ease-of-use API on top of PyTorch to allow users to easily get the best performance from Intel HWs. In particular, IPEX extends the dispatch mechanism of PyTorch to automatically handle type conversions and layout conversions.
- Graph optimization passes and custom kernels on top of oneDNN for maximizing the HW efficiency.
- Custom compound ops for speeding up key DL modules, e.g. the interaction module from DLRM.
Intel collaborates with Facebook to continuously upstream most of the optimizations from IPEX to PyTorch proper to better serve the PyTorch community with the latest Intel HW and SW advancements.
oneAPI Deep Neural Network Library (oneDNN)
oneDNN is an open-source cross-platform performance library of basic building blocks for deep learning applications. The library is optimized for Intel Architecture Processors, Intel Processor Graphics and Xe architecture-based Graphics. It also supports the computation of a variety of data types including FP32, BF16 and INT8.
oneDNN is the performance library that IPEX relies on to optimize performance-critical deep neural network operations (convolution, matrix multiplication, pooling, batch normalization, non-linearities etc.). oneDNN also supports fusion kernels as computation primitives for common DL patterns like convolution or matrix multiplication plus a sequence of element-wise post-operations. These primitives are used by IPEX to implement graph fusion optimization.
Hardware advancements
Intel’s 3rd gen Xeon Scalable processors have AVX512_BF16 instructions that add BF16→ FP32 fused multiply-add (FMA) and FP32→BF16 conversion that double the theoretical compute throughput over FP32 FMAs. In addition, this hardware natively supports INT8 FMAs introduced in the previous generation, which quadruples the theoretical compute throughput over FP32 FMAs. VCVTNEPS2BF16 and VCVTNE2PS2BF16 instruction converts packed FP32 data to one packed BF16 data, which holds twice the number of values. VDPBF16PS instruction to perform the dot product.
 Figure 1. AVX512_BF16 instruction set introduced in 3rd gen Intel Xeon Processor adds new instructions for converting and operating on bfloat16
Figure 1. AVX512_BF16 instruction set introduced in 3rd gen Intel Xeon Processor adds new instructions for converting and operating on bfloat16
Ease-of-Use IPEX User-facing API
IPEX brings “3-step” user-facing API to enable BF16 and oneDNN optimizations on CPU:
- User imports “intel_pytorch_extension” Python module to register IPEX optimizations for op and graph into PyTorch.
- User calls “ipex.enable_auto_mixed_precision(mixed_dtype=torch.bfloat16)” to enable BF16 auto-mixed precision². Automatic layout conversion is enabled by default.
- User calls “to(ipex.DEVICE)” on both PyTorch modules and input tensors to enable IPEX optimizations. All IPEX optimizations are implemented on “ipex.DEVICE” rather than PyTorch vanilla CPU.
Following, we provide examples in pseudo Python code for PyTorch BF16 inference and training with IPEX API. The three steps are highlighted with yellow marks. These are the only changes to original user code.
Users are required to install IPEX, either from the binary package available in Intel® AI Analytics Toolkit or via build from source, to take advantage of the ease-of-use API and the performance boost. Users shall use Intel® processors with Intel® AVX-512 instruction support to take advantage of optimizations in IPEX, and use the 3rd Gen Intel® Xeon® scalable processors or later generations to take advantage of the BF16 performance boost.
Under the hood, IPEX registers optimized op kernels on “ipex.DEVICE” with “torch::RegisterOperators” PyTorch extension API and registers graph fusion pass with “torch::jit::RegisterPass” PyTorch extension API when the user imports IPEX Python module.
IPEX automatically converts input tensor layout to blocked layout for PyTorch ops optimized with oneDNN kernels and only converts the tensor to strided layout on demand when non-oneDNN ops are encountered. This maximizes oneDNN kernel efficiency without introducing unnecessary layout conversions. When the user turns on BF16 auto-mixed precision, IPEX automatically inserts type conversions between BF16 and FP32 according to the list of supported BF16 ops. IPEX applies graph fusion for patterns supported by oneDNN, pattern examples including “conv2d+relu”, “conv2d+swish”, “conv2d+add+relu”, “linear+relu” and “linear+gelu” etc. These are common patterns in popular DL models like DLRM, BERT and ResNet.
Performance Result
We evaluated the performance boost of PyTorch BF16 training and inference with IPEX and oneDNN on DLRM, BERT-Large and ResNext-101–32x4d, covering three representative DL tasks: recommendation, NLP and CV respectively. The performance speed-up is compared with that of FP32 on PyTorch proper, and is contributed by BF16 support, layout conversion optimization and graph optimization from IPEX.
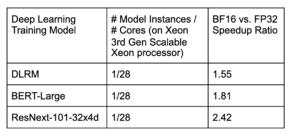
Table 1. Single instance BF16 training performance gains over baseline (FP32 with Intel® Math Kernel Library for DLRM and BERT-Large, FP32 with Intel® oneDNN for ResNext-101–32x4d), measured on single-socket Intel(R) Xeon(R) Platinum 8380H Processor with 28 cores. The DLRM model uses 2K mini-batch-size with Criteo terabyte dataset, and the hyper-parameters use the MLPerf configuration. The BERT-large model uses 24 mini-batch-size with WikiText dataset. The ResNext-101–32x4d uses 128 mini-batch-size with ILSVRC2012 dataset.
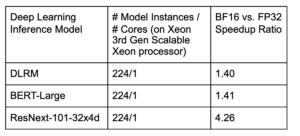
Table 2. Multi-instance BF16 inference performance gains over baseline (FP32 with Intel® Math Kernel Library for DLRM and BERT-Large, FP32 with Intel® oneDNN for ResNext-101–32x4d), measured on 8-socket Intel(R) Xeon(R) Platinum 8380H Processor with 28 cores per socket. The DLRM model uses 64 mini-batch-size per instance with Criteo terabyte dataset, and the hyper-parameters use the MLPerf configuration. The BERT-large model uses 1 mini-batch-size with WikiTest dataset. The ResNext-101–32x4d uses 1 mini-batch-size with ILSVRC2012 dataset.
The speedup ratio of ResNext-101–32x4d is larger than the other two models because it benefits more from layout conversion optimization and graph fusion optimization, e.g. batch-normalization folding, conv fused with relu and conv fused with add and relu.
Conclusion
In this blog, we introduced recent SW advancements in both user experience and performance for PyTorch CPU BF16 support using IPEX and oneDNN. With these SW advancements, we not only demonstrated the ease of use of IPEX API but also showcased 1.55X-2.42X speed-up with IPEX BF16 training over FP32 with PyTorch proper and 1.40X-4.26X speed-up with IPEX BF16 inference over FP32 with PyTorch proper. Both IPEX and oneDNN are available as open source projects. oneDNN is released as part of oneAPI optimization libraries, and IPEX is released as part of oneAPI-powered Intel AI analytics toolkit.
Acknowledgements
A special thanks to Jianhui Li (Principle Engineer from Intel) and Chris Gottbrath(Technical Program Manager from Facebook), who kindly reviewed the blog. Also appreciate contributions from Eikan Wang, Haozhe Zhu and Jiayi Sun from Intel who developed the optimizations in IPEX and did the performance benchmarking.
About the Authors
Jiong Gong is a senior software engineer at Intel® architecture, Graphics and Software group where he is a software architect on PyTorch framework optimization for Intel Architecture and one of the major contributors to low-precision inference solutions on IA. He has 8 years of full-stack experience in artificial intelligence from various AI applications to framework, library and compiler optimizations. Jiong received his master’s degree in computer science from Shanghai Jiao Tong University.Nikita Shustrov is a senior software engineer in Intel® oneDNN library where he works on optimizations of computational deep learning primitives for Intel Xeon CPUs. He has over 10 years of experience working on HPC and low-level optimizations at Intel. Nikita received his master’s degree in computer science from Novosibirsk State University.Vitaly Fedyunin is a software engineer at Facebook, where he works on various PyTorch performance optimization projects. He had over 16 years of full-stack experience developing and optimizing multiple frameworks, libraries, and pipelines.
Citations
¹ Some pull requests have not been merged yet
² Model runs with FP32 optimization if this step is skipped. Auto-layout conversion still applies for FP32
Configuration Details
Hardware
Intel(R) Xeon(R) Platinum 8380H Processor, 8 socket, 28 cores HT On Turbo ON Total Memory 1536 GB (48 slots/ 32GB/ 3200 MHz),
Firmware
BIOS: WLYDCRB1.SYS.0017.P06.2008230904 (ucode: 0x700001e)
OS
Ubuntu 20.04.1 LTS, kernel 5.4.0–48-generic
Compiler
GCC: 7.5.0
Frameworks and Libraries
PyTorch (v1.5.0-rc3): https://github.com/pytorch/pytorch.gitIntel Extension for PyTorch (IPEX) (1.1.0 preview used by the benchmarks in the blog): https://github.com/intel/intel-extension-for-pytorch/tree/1.1.0_previewoneDNN (v1.5-rc): https://github.com/oneapi-src/oneDNN
Workloads
DLRM
Training batch size (FP32/BF16): 2K/instance, 1 instance on a CPU socketInference batch size (FP32/BF16): 64/instance, 28 instances sharing model weights and running in a single process per socket, 224 instances on 8 CPU sockets in total.Dataset (FP32/BF16): Criteo Terabyte DatasetCode: https://github.com/facebookresearch/dlrm.git Commit ID: 52b77f80a24303294a02c86b574529cdc420aac5
BERT-Large
Training batch size (FP32/BF16): 24/instance, 1 instance on a CPU socketInference batch size: 1/instance, 1 instance per process, 224 instances on 8 CPU sockets in total.Dataset (FP32/BF16): WikiText-2Code: https://github.com/huggingface/transformers Commit ID: 1a779ad7ecb9e5215b6bd1cfa0153469d37e4274
ResNext-101–32x4d
Training batch size (FP32/BF16): 128/instance, 1 instance on a CPU socketInference batch size (FP32/BF16): 1/instance, 1 instance per process, 224 instances on 8 CPU sockets in total.Dataset (FP32/BF16): ILSVRC2012Code: https://github.com/pytorch/vision
Reproducing Steps
https://github.com/intel/intel-extension-for-pytorch/tree/1.1.0_preview/examplesTested by Intel as of 11/4/2020.Notices & DisclaimersPerformance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.Your costs and results may vary.Intel technologies may require enabled hardware, software or service activation.© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Fujitsu and RIKEN Optimized oneDNN for Improved Performance on ARM
Claiming the title of world’s fastest performance for the number of deep learning models trained per time unit for CosmoFlow, Fujitsu and RIKEN take first...
Edge Intelligence and Its application in CAVs
Intel’s oneDNN 2.1 Released With NVIDIA GPU Support, Initial Alder Lake Optimizations
Out today is a new release of Intel’s open-source oneDNN library used as a deep neural network library for assembling deep learning applications.