
Speed Training 8X Using PyTorch with oneCCL Backend
Train Complex Models in Hours, Not Days, with Distributed Training
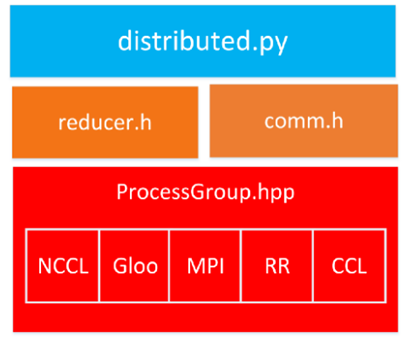
Fig.1 Software stacks for PyTorch DistributedDataParallel. CCL is one of the communication backend options.
As today’s deep learning models expand exponentially, so do their parameters, growing by orders of magnitude. The solution for processing those models in a timely manner: distributed training. This article recounts how a research team distributed its deep learning recommender model (DLRM) by using PyTorch with different backends, to reveal an 8.5X performance increase training AI topologies with the Intel oneAPI Collective Communications Library (oneCCL) backend. The Intel oneCCL, designed to promote compatibility and enable developer productivity, assists developers and researchers to train new, more complex models employing optimized communication patterns to distribute model training across multiple nodes.
Developer Story: How We Ported oneDNN to Fugaku with Arm
Fujitsu optimized and ported the oneDNN DL process library software for the Armv8-A instruction set so that it can be run at high speed on...
Building an Open AI & HPC Ecosystem
Speed Training 8X Using PyTorch with oneCCL Backend
Train Complex Models in Hours, Not Days, with Distributed Training Fig.1 Software stacks for PyTorch DistributedDataParallel. CCL is one of the communication backend options. As...